Prem Seetharaman
Senior Research Scientist, Adobe Research
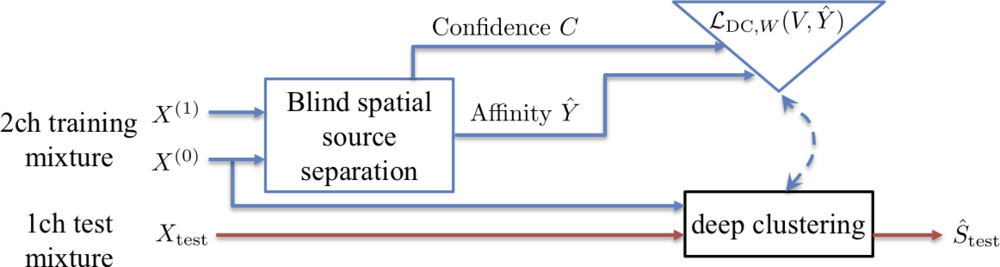
Separating an audio scene into isolated sources is a fundamental problem in computer audition, analogous to image segmentation in visual scene analysis. Source separation systems based on deep learning are currently the most successful approaches for solving the underdetermined separation problem, where there are more sources than channels. Traditionally, such systems are trained on sound mixtures where the ground truth decomposition is already known. Since most real-world recordings do not have such a decomposition available, this limits the range of mixtures one can train on, and the range of mixtures the learned models may successfully separate. In this work, we use a simple blind spatial source separation algorithm to generate estimated decompositions of stereo mixtures.
These estimates, together with a weighting scheme in the time-frequency domain, based on confidence in the separation quality, are used to train a deep learning model that can be used for single-channel separation, where no source direction information is available. This demonstrates how a simple cue such as the direction of origin of source can be used to bootstrap a model for source separation that can be used in situations where that cue is not available.
This work was a collaboration with Mitsubishi Electric Research Labs (MERL).