Prem Seetharaman
Senior Research Scientist, Adobe Research
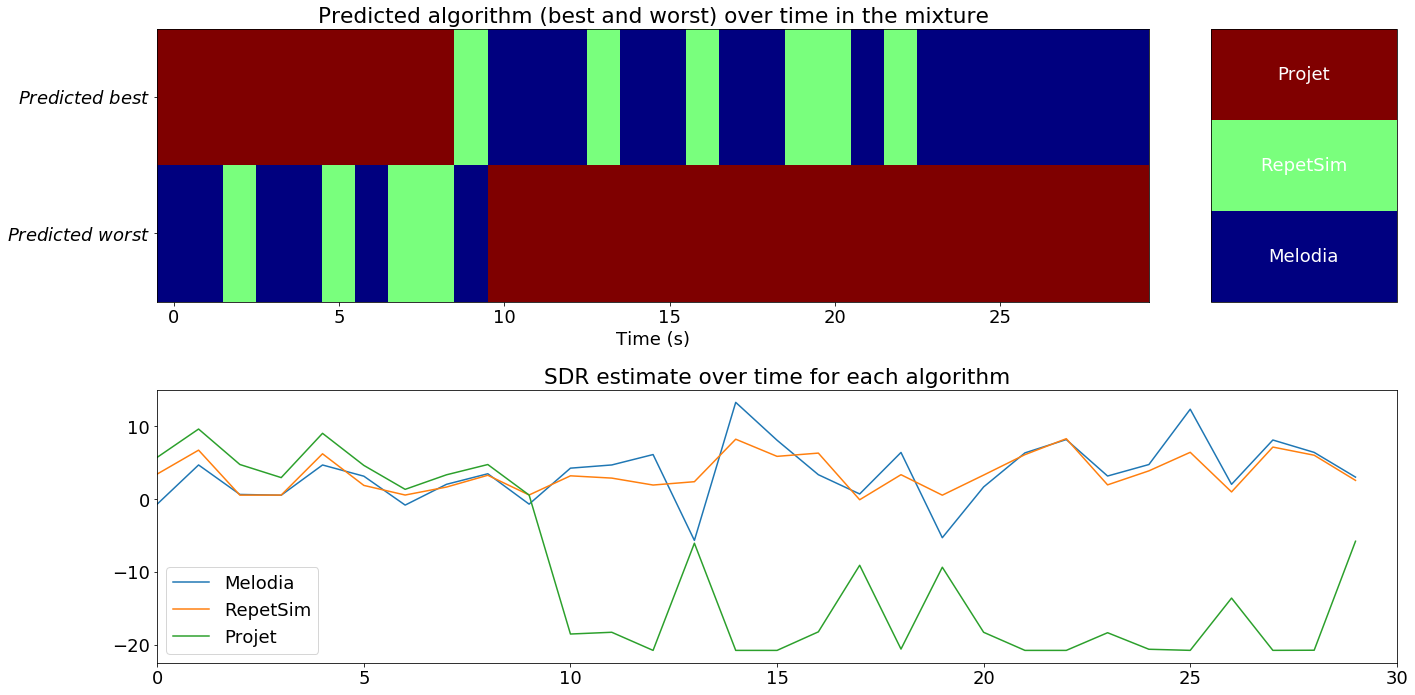
Audio source separation is the process of decomposing a signal containing sounds from multiple sources into a set of signals, each from a single source. Source separation algorithms typically leverage assumptions about correlations between audio signal characteristics (“cues”) and the audio sources or mixing parameters, and exploit these to do separation. We train a neural network to predict quality of source separation, as measured by Signal to Distortion Ratio, or SDR. We do this for three source separation algorithms, each leveraging a different cue - repetition, spatialization, and harmonicity/pitch proximity. Our model estimates separation quality using only the original audio mixture and separated source output by an algorithm. These estimates are reliable enough to be used to guide switching between algorithms as cues vary. Our approach for separation quality prediction can be generalized to arbitrary source separation algorithms.